The SDCC Analysis Portal provides access to an array of computing resources that can be used for interactive data analysis through Jupyter notebooks on multiple platforms. The core software behind the analysis portal is Jupyterhub, which provides a multi-user web service that instantiates and manages Jupyter notebooks. Our service provides the next-generation Jupyterlab interface by default, but a classic notebook session can be used as well.
This page is intended to provide a guide for accessing and utilizing this analysis portal.
Logging in to the Portal
The portal is accessed through a load-balancing web proxy located at https://jupyter.sdcc.bnl.gov/. The proxy offers redirection to multiple entry points depending on the resources required. Currently, there are two types of entry points:
- HTC: ("High Throughput Computing") Provides access to the SDCC compute farm, including HTCondor shared pool queues.
- HPC: ("High Performance Computing") Provides access to GPU computing resources on the Institutional Cluster or the KNL Cluster via Slurm.

Selecting the "Launch" button for a given entry point will redirect you to a login page. Login requires a standard SDCC username and password; however, because these servers provide interactive access to the SDCC, two-factor authentication is necessary. Once a correct username and password are entered, your identity is further verified by requesting a one-time password code. The procedure requires a smartphone using either the FreeOTP or GoogleAuthenticator app (if you do not have a smartphone, there is an alternative method using a Chrome browser extension with Google Authenticator). When logging in for the first time, you will be presented with a QR code that can be used to link the account with either app. Once the account is linked, subsequent logins will request a one-time code, provided by the app, as indicated below:
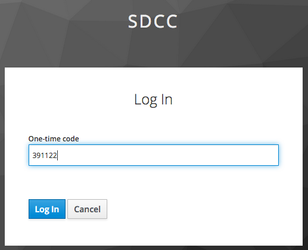
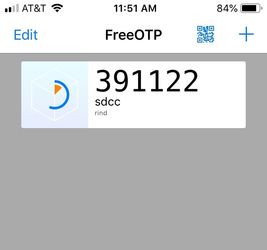
Once the code is entered successfully, the hub will launch a Jupyter session for you. If you are using the HPC portal, you will be asked for further parameters defining your resource request to the Slurm batch system. The form for the Institutional Cluster appears as follows:

In order to run your Jupyter session on the IC, you must select a valid partition and account, as well as the GPU type and the wall clock limit for your job. For information on obtaining access to any of the SDCC HPC clusters, please see https://www.sdcc.bnl.gov. Note that the IC is a shared resource, so if your request exceeds currently available resources, you will be placed in a wait queue. Alternatively, you can also run "locally" on a Jupyterhub node by checking the small box in the lower left corner. This will provide limited compute resources, but you will have access to Slurm commands that allow you to submit jobs from that host.
Using Jupyterlab
Once your Jupyter session starts up, you will be presented with a Jupyterlab interface that appears as follows:
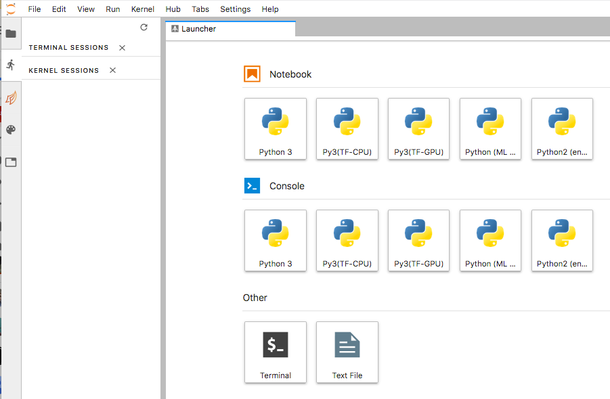
In order to start a new Jupyter notebook from the Launcher, simply click on one of the available kernels. An interactive terminal can be started in the same manner. Selecting the folder icon on the left side will open a filesystem interface. Previously saved notebooks (with a .ipynb file extension) can be open by double-clicking them in this interface. Tabs can be dragged and opened in side-by-side views, both vertically and horizontally. For more information, consult the Jupyterlab documentation.
Logging out of the Portal
In order to log out of a "local" session, simply select the "Hub" pulldown menu and "Logout":
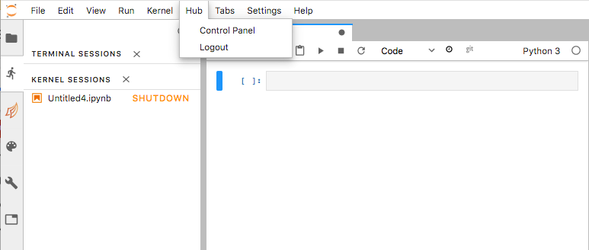
If you are running a Slurm session on the IC or KNL cluster, you must add an additional step to ensure that your batch job is not left running and using up your allocation on the cluster. Instead of selecting "Logout," select "Control Panel" and click on the  button. This will kill your running job and give you the option to restart it. At this point, you may safely log out using the button in the upper right corner.
button. This will kill your running job and give you the option to restart it. At this point, you may safely log out using the button in the upper right corner.
Note: Simply closing your browser window will not immediately kill your Jupyter session. If this does happen, logging back in will, in most cases, reconnect you to your previous session. After thirty minutes, a culling process will eventually kill any unconnected session (note: a running batch session may also be killed by the batch system if it exceeds the allowed resources, e.g. time, memory, etc.).
Troubleshooting
For best response regarding any issues relating to Jupyterhub, please open an RT ticket in the Linux Farms queue.
Related articles